安装
使用 docker-compose 安装,docker-compose.yml 文件如下:
version: '3.8'
services:
embyserver-happy:
image: amilys/embyserver
platform: linux/amd64 # 强制使用 amd64 架构(我这里使用的是 arm64 版本,如果使用 amd64 版本,请删除此行)
container_name: emby-happy
privileged: true
volumes:
- ./emby/config:/config # 配置文件
- ./emby/webdav:/docker/webdav # 挂载 webdav 目录
- ./emby/local:/docker/local # 本机影音文件目录
ports:
- 8096:8096
restart: unless-stopped在浏览器中访问 http://localhost:8096 即可访问 Emby。
挂载目录
挂载目录为 ./emby/local,目录结构如下:
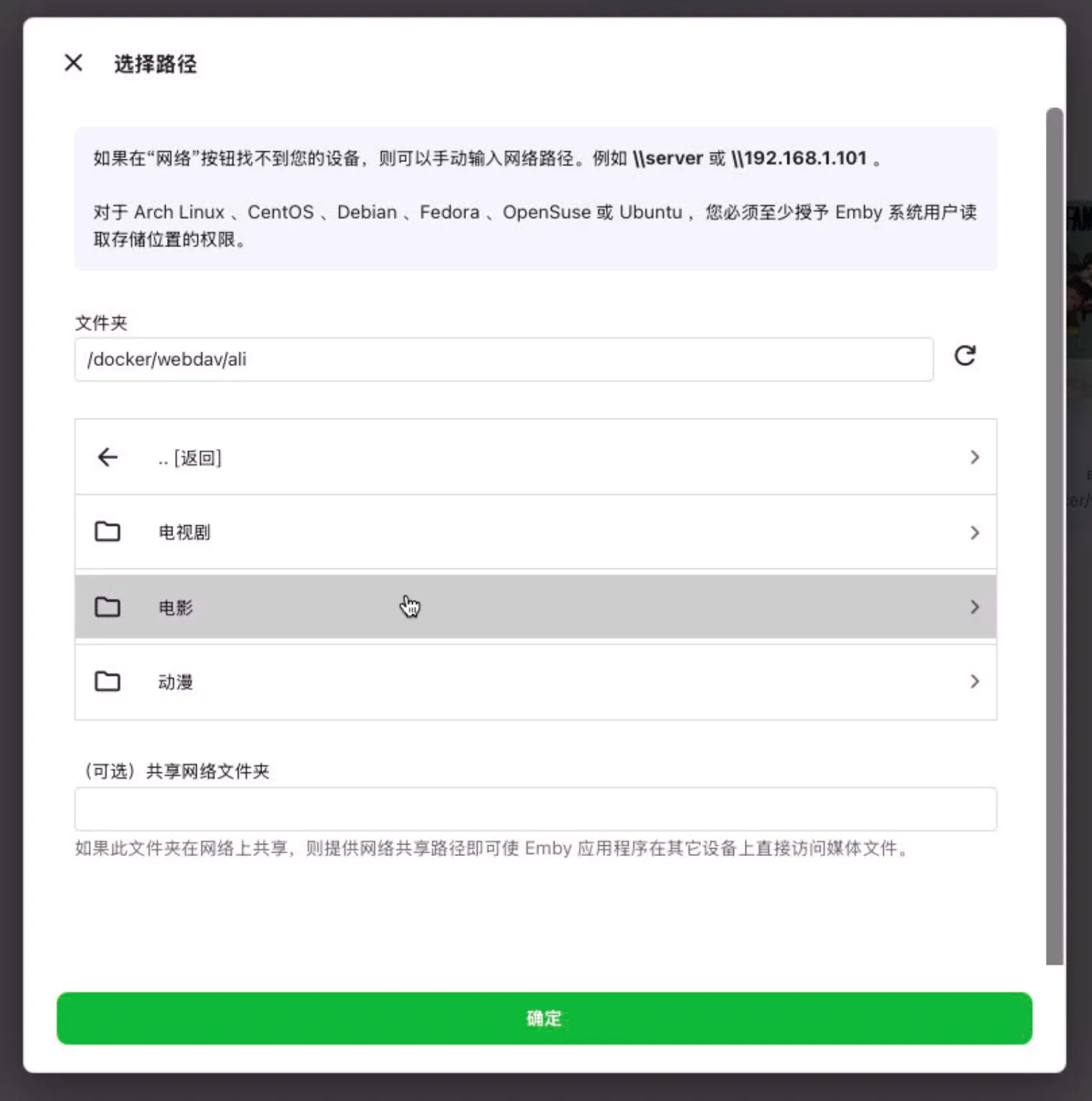
在 ./emby/local 目录下存放你的影音文件,然后在浏览器访问 emby 服务,进入 设置 -> 服务器 -> 媒体库 -> 添加媒体库 -> 选择 从文件夹添加,然后选择 /docker/local 目录,然后扫描,等待扫描完成后,你就可以在首页中看到你的影音文件了。
第三方播放
使用 Infuse、Forward、VidHub、Senplay 等第三方播放器,可以播放 emby 中的影音文件。
局限
随着影视资源库的不断扩充,对于本地存储的容量要求也越来越高,此时有两条路可以选择
- 使用 NAS 存储
- 使用云盘挂载
对于 NAS 存储,这需要一笔不小的开支,而且需要考虑电费、散热、噪音等问题。
而我之前使用的是阿里云盘,且开通了它的三年会员,所以就自然而然选择了云盘挂载。
云盘挂载
总体思路是将云盘转换成 webdav 服务,然后在将 webdav 挂载为本地目录。
1.云盘转 webdav
使用 alist 很方便的将云盘转换成 webdav 服务,只需要在 alist 中添加阿里云盘即可。
TIP如果你没有阿里云盘的第三方权益会员,可以参考 alist 挂载阿里云盘 实现获取 阿里云盘
TV token解除限速。
2.1 使用 Rclone 挂载为本地目录
可以使用 Rclone 挂载 webdav 为本地目录,然后使用 emby 添加此目录。
- 安装 Rclone
macos 不能使用brew 安装,需要使用源码安装。
curl https://rclone.org/install.sh | sudo bash- 配置 Rclone
rclone config根据提示创建 remote -> 输入名称 -> 选择 webdav -> 输入 url -> 选择 Other site/service or software -> 输入用户名 -> 选择 Yes, type in my own password -> 输入两次密码 -> 回车完成配置
TIPurl 为 alist 的 webdav 地址,例如:
https://example.com/dav/,用户名密码为你的 alist 用户名密码。
- 挂载 webdav
# 直接后台挂载
rclone mount mywebdav:/ ~/docker/emby/webdav --network-mode --cache-dir cache --vfs-cache-mode full --header "Referer:" --daemon
# 使用 tmux 挂载
tmux new-session -d -s mount-rclone rclone mount mywebdav:/ ~/docker/emby/webdav --network-mode --cache-dir cache --vfs-cache-mode full --header "Referer:" --daemon
# 关闭挂载
#macos 使用
umount ~/docker/emby/webdav
#windows、linux 使用
fusermount -u ~/docker/emby/webdavTIP
rclone mount: 挂载命令
mywebdav:: 刚刚配置的 remote 名称
~/docker/emby/webdav: 你的挂载目录
--network-mode: 启用网络模式,该模式会让 rclone mount 使用网络流量来访问和同步文件,而不是使用本地缓存。这可以有效减少磁盘占用,但会使文件访问速度依赖于网络连接。
--cache-dir cache: 设置本地缓存目录。在此命令中,cache 是一个相对路径或绝对路径,指定 rclone 存储本地缓存的地方。缓存的文件可以加速后续访问操作,尤其是针对大量小文件或频繁访问的情况。
--vfs-cache-mode full: FS(虚拟文件系统)缓存模式。在 rclone mount 中,full 模式表示 rclone 将缓存文件的全部内容。这对于大型文件(例如视频文件)的操作尤其重要,因为它将所有文件数据保存在本地缓存中,从而提高性能。该模式确保每个文件都完全缓存并能够进行读取和修改。
--header "Referer:": 必须加上,否则无法播放
--daemon: 后台运行
WARNING由于缓存的原因,可能导致挂载后再网盘处编辑文件,挂载的目录不会同步更新,此时需要手动关闭挂载,重新挂载。
2.2 使用 strm 文件模拟本地目录
思路来自于:
大体思路就是在 emby 的挂载目录中存放和 alist 1:1 一样的目录结构,但是文件内容由 mp4 -> strm 文件。
且 strm 文件内容为 webdav 的 url 地址,emby 会自动识别 strm 文件,并进行播放。
我在使用 emby-alist 仓库的代码时发现它存在一个 bug 无法识别所有的文件目录,因此我对它进行了修改,并添加了下载字幕的功能。
IMPORTANT# 替换 webdav_url、save_mulu、username、password 为你自己的参数 webdav_url = 'https://example.com/dav/folder/' # alist webdav 地址 folder 为你的文件夹名称 save_mulu = './' # 输出路径 username = '' # 用户名 alist 用户名 password = '' # 密码 alist 密码 download_subtitle = False # 是否下载字幕文件
from webdav3.client import Client
import os, time, requests
def list_files(webdav_url, username, password):
# 创建WebDAV客户端
options = {
'webdav_hostname': webdav_url,
'webdav_login': username,
'webdav_password': password
}
client = Client(options)
mulu = []
wenjian = []
q = 1
while q < 15:
try:
# 获取WebDAV服务器上的文件列表
files = client.list()
except:
q += 1
print('连接失败,1秒后重试...')
time.sleep(1)
else:
if q > 1:
print('重连成功...')
break
if q >= 15:
print(f"连接 {webdav_url} 失败,已达到最大重试次数")
return [], []
for file in files[1:]:
if file[-1] == '/':
mulu.append(file)
else:
wenjian.append(file)
return mulu, wenjian
def traverse_webdav(base_url, username, password, max_depth=10, current_depth=0):
"""
递归遍历WebDAV目录,获取所有目录和文件
Args:
base_url: WebDAV基础URL
username: 用户名
password: 密码
max_depth: 最大递归深度,防止无限递归
current_depth: 当前递归深度
Returns:
tuple: (所有目录列表, 所有文件URL列表)
"""
if current_depth >= max_depth:
print(f"警告: 达到最大递归深度 {max_depth},停止在 {base_url} 的递归")
return [], []
print(f"扫描目录: {base_url}")
# 获取当前目录下的文件和子目录
directories, files = list_files(base_url, username, password)
all_directories = [base_url]
all_files = [base_url + f for f in files]
# 递归处理子目录
for directory in directories:
dir_url = base_url + directory
sub_dirs, sub_files = traverse_webdav(dir_url, username, password, max_depth, current_depth + 1)
all_directories.extend(sub_dirs)
all_files.extend(sub_files)
return all_directories, all_files
def process_media_file(file_url, save_path, webdav_url):
"""处理媒体文件,创建.strm文件"""
if not os.path.exists(save_path + file_url.replace(webdav_url, '')[:-3] + 'strm'):
print('正在处理:' + file_url.replace(webdav_url, ''))
try:
os.makedirs(os.path.dirname(save_path + file_url.replace(webdav_url, '')[:-3] + 'strm'), exist_ok=True)
with open(save_path + file_url.replace(webdav_url, '')[:-3] + 'strm', "w", encoding='utf-8') as f:
f.write(file_url.replace('/dav', '/d'))
except:
try:
# 处理包含冒号等特殊字符的文件名
os.makedirs(os.path.dirname(save_path + file_url.replace(webdav_url, '').replace(':', '.')[:-3] + 'strm'), exist_ok=True)
with open(save_path + file_url.replace(webdav_url, '').replace(':', '.')[:-3] + 'strm', "w", encoding='utf-8') as f:
f.write(file_url.replace('/dav', '/d'))
except Exception as e:
print(f"处理失败: {file_url.replace(webdav_url, '')} - 错误: {str(e)}")
print(f"{file_url.replace(webdav_url, '')}处理失败,文件名包含特殊符号,建议重命名!")
def download_subtitle_file(file_url, save_path, webdav_url):
"""下载字幕文件"""
if not os.path.exists(save_path + file_url.replace(webdav_url, '')):
p = 1
while p < 10:
try:
print('正在下载:' + save_path + file_url.replace(webdav_url, ''))
r = requests.get(file_url.replace('/dav', '/d'))
os.makedirs(os.path.dirname(save_path + file_url.replace(webdav_url, '')), exist_ok=True)
with open(save_path + file_url.replace(webdav_url, ''), 'wb') as f:
f.write(r.content)
except Exception as e:
p += 1
print(f'下载失败,1秒后重试... 错误: {str(e)}')
time.sleep(1)
else:
if p > 1:
print('重新下载成功!')
break
if p >= 10:
print(f"下载失败: {file_url.replace(webdav_url, '')} - 已达到最大重试次数")
# 主程序
if __name__ == "__main__":
# 输入WebDAV地址、用户名和密码
webdav_url = 'https://example.com/dav/folder/' # alist webdav 地址 folder 为你的文件夹名称
save_mulu = './' # 输出路径
username = '' # 用户名 alist 用户名
password = '' # 密码 alist 密码
# 控制是否下载字幕文件
download_subtitle = False # 设置为 False 将不会下载字幕文件
# 设置最大递归深度
max_depth = 10 # 可以根据实际需求调整
print(f"开始遍历 WebDAV 目录: {webdav_url}")
print(f"字幕下载功能: {'已启用' if download_subtitle else '已禁用'}")
start_time = time.time()
# 递归遍历所有目录和文件
all_directories, all_files = traverse_webdav(webdav_url, username, password, max_depth)
print(f"遍历完成,共发现 {len(all_directories)} 个目录,{len(all_files)} 个文件")
print(f"遍历耗时: {time.time() - start_time:.2f} 秒")
# 处理所有文件
processed_count = 0
media_count = 0
subtitle_count = 0
for file_url in all_files:
extension = file_url.split('.')[-1].upper() if '.' in file_url else ''
if extension in ['MP4', 'MKV', 'FLV', 'AVI']:
process_media_file(file_url, save_mulu, webdav_url)
processed_count += 1
media_count += 1
elif extension in ['ASS', 'SRT', 'SSA'] and download_subtitle:
# 只有当 download_subtitle 为 True 时才下载字幕文件
download_subtitle_file(file_url, save_mulu, webdav_url)
processed_count += 1
subtitle_count += 1
print(f'处理完毕!共处理 {processed_count} 个文件(媒体文件: {media_count}, 字幕文件: {subtitle_count})')
print(f'字幕下载功能: {"已启用" if download_subtitle else "已禁用"}')
input('按任意键退出...')TIP经测试无法通过 emby 播放 strm 文件,但是通过第三方播放器则可以正常播放。
emby 添加资源库
在 emby 中添加资源库,选择 从文件夹添加,然后选择 /docker/emby 目录,然后扫描,等待扫描完成后,你就可以在首页中看到你的影音文件了。